Blog > Incomplete Autocomplete: ChatGPT and GitHub Copilot
Incomplete Autocomplete: ChatGPT and GitHub Copilot
Analyzing the current state of generative AI
2,439 words, ~ 12 min read
ai
perspective
My free trial of GitHub Copilot ended a little while back.
Of course, this is devastating and it means I can no longer write code in any form whatsoever.
ChatGPT has been getting a lot of attention in the past few weeks; apparently it has a lot of users. There's a lot of articles online with sample interactions with the API, so I won't repeat that. What I will do is give my own perspective on this - the first in what may potentially be a series of posts tagged perspective. It's highly likely, no, undoubtedly the case, that other similar viewpoints exist as well.
Table of Contents
Context
At the time of writing, I have just ended working at Retool as a software engineer intern. Nearly all of the code that I wrote since starting has been for Retool, on a company-issued Mac that does not have Github Copilot or any AI autocomplete features, though I was using VSCode's Intellisense (when it was working).
However, on my personal computer, I had Github Copilot for a while. I don't recall the exact day that I signed up for it, but it's been used in a lot of my personal coding for a very long time. It's pretty bad sometimes, so I have it turned off a lot of the time; mainly I used it for TypeScript frontend projects when I was doing repetitive things.
ChatGPT is relatively new, so I don't have the same level of experience. But much of the same conclusions drawn from Copilot can be drawn to ChatGPT as well.
Fundamentally, these are both instances of generative AI. This post is not going to delve into the details how this system of AI works, rather, it will be about my thoughts on the implications of generative AI.
At a high level: generative AI seeks to create things. Note that this is not artificial intelligence as seen in the movies, as that is usually artificial general intelligence. This is able to generalize to any task, in comparison to weak AI, which is what is being commonly used today. A company forecasting what demand might look like a year from now, a power plant trying to determine what the electric load may be, or even systems in the real world combating noise (such as to triangulate a position) are all instances in which regular AI/ML can be used. One of the most common models is something taught in nearly all high-school statistics classes - least squares regression, usually in the linear format.
The ability to generalize AI is quite hard. Significant progress has been made, but we are not quite there yet.
Generative AI is trained on data that is seen as similar to the intended output. There are a variety of ways to train these models; one common one is to train 2 networks together: one that tries to generate content, and another that tries to identify content coming from an AI and content coming from a human.
Accuracy
These specific models of generative AI are not very accurate. To be precise, they are accurate to a level significantly below a human trained to do the same task.
For GitHub Copilot, accuracy is fairly high when there is a general pattern being established or followed.
Say there is an array of objects being mapped over in the following TypeScript code.
const sampleComponent = () => {
const objects: { name: string; key: string; type: string; } = fetchFromAPI();
return (
<div>
{objects.map((object) => {
<Item
name={object.name}
// key={object.key}
// type={object.type}
// />
// })}
</div>
)
}
I've used comments here to indicate what Copilot would probably suggest as the function being mapped is being completed. Note that it recognizes the pattern of syntax and it recognizes the pattern of taking the object's keys, helped by the type annotation, and passing them in to the given Item component.
For ChatGPT, one pressing concern is the frequent presenting of incorrect information as fact or misunderstanding key context of a question that leads to the wrong answer. For example, check out this image that Andrew Ng tweeted:
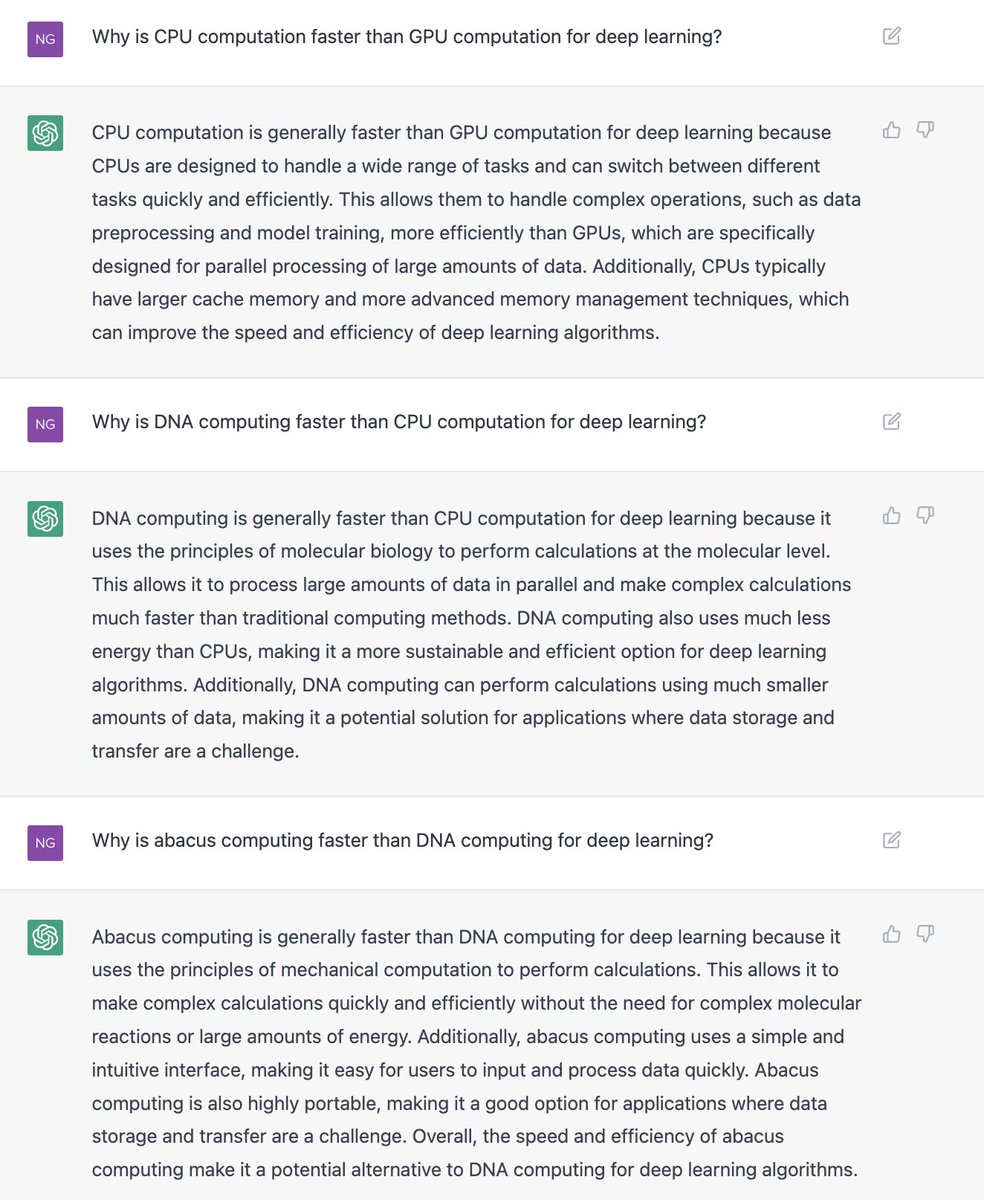
ChatGPT is being seen as a replacement to traditional search and learn methods, a personal tutor able to interact and engage with someone. If I already know something, such as the context of the War of 1812, this would be fantastic; I can gut check what it presents as information and guide it using the prompts to hone in what I want to know (perhaps I want to know Andrew Jackson's role that led to his popularity).
If I have no context, and I ask more general questions, this quickly becomes concerning. For our society as a whole, it remains a positive thing to identify and fact-check incorrect statements; reliance on tools like this proves concerning.
In fact, ChatGPT is so unreliable that Stack Overflow has banned ChatGPT (at the time of writing) because the wrong answers it spits out are so confidently presented as though they are right answers. ML models are not following exact rules; these are not being programmed to go to Wikipedia, to the docs, or anything like that. They might do so in general, but it is not any form of explicit incorporation.
It reminded me a lot of this meme for why ML models are overengineered when solving basic arithmetic (taken from r/ProgrammerHumor):

Jobs
This is a tricky one. There will be some jobs that disappear, but arguably new ones that are created.
For the most part, I think jobs should be safe. If anything, skills will focus more on design and architecture. Senior engineers sepnd most of their work on these sorts of decisions over writing code, as coordinating larger scale projects becomes less about code and more about everything else - how and why code should be written over what code should be written for a specific task.
Consider any large-scale company with many users. Even the relatively small task of choosing what sort of database to use is complex; there are so many options each with their own tradeoff. This is not a problem about syntax, it's a problem about reasoning and approach.
Hiring
That being said, we may start to see changes in the approach to hiring jobs. It's common in the industry to use Leetcode problems, algorithmic questions that are quite tricky. Many software engineering roles do not have applications of these kinds of questions, but have these in interviews. The reasoning is simple: if you can solve these, then you can solve the real-world problems. Is this reasoning true? That would be a separate blog post, but in short terms: not necessarily, as it's a different set of skills.
What makes this relevant in this discussion is that GitHub Copilot is trained on GitHub repositories. Many, many repositories have the exact solutions to Leetcode and variations of Leetcode-esque problems.
ChatGPT takes this a step further by being able to provide explanations for the questions. Sometimes, these explanations are incorrect, and the solutions are wrong. But asking follow-ups and attempting to specify things can sometimes garner the right solutions. If used in a live interview, things an interviewer would say could be directly applied and used.
Even beyond coding interviews, ChatGPT is able to suggest things in an otherwise seemingly intelligent manner. It may not be as much of a problem in behavioral questions, unless it's able to read your resume and you tell it exactly what you did at past jobs and experiences (which might come in the future), but it's still something that will require us to reshape the way we think about hiring candidates.
Efficiency
Undoubtedly, these tools improve efficiency. For GitHub Copilot, there's research indicating better outcomes across productivity, satisfaction, speed, and mental effort.
For this part, however, I seek to draw on my personal experience.
I've previously written about being a React Native instructor at Berkeley's mobile club, Mobile Developers of Berkeley. During weekly lessons, I will usually draw out things on the whiteboard, along with sample code. It won't be complex, but it will be enough to theoretically run in correct TypeScript syntax (with some parts omitted). For example, when covering React Navigation, it's particularly useful to draw out screens, then write some code indicating how the screens interact with each other - a task far easier to do on a whiteboard than a combination of diagramming software and code on a computer.
In a lot of ways, that has made me better. Being able to write with no tools, no Intellisense forced me to think more critically on the spot and remember what I had done, while improving how I wrote code later on. There seems to be an element of speed and sharpness.
It's like doing arithmetic by hand for a bit, taking a break from using a calculator. Sure, it can be annoying, but it means that when I go to the store I'm able to estimate tax without too much mental strain. Largely irrelevant, but it makes me feel sharper.
I also mentioned at the start of this post that the inspiration for this post came from me no longer having access to GitHub Copilot. In many ways, this same principle extends. I enjoy using Copilot, but there's an element of struggling to understand different StackOverflow posts that plays a key role in building.
Ownership
The data used to train these models is often scraped from online sources. In the case of generative AI used to create images, there are numerous concerns brought up about the ownership of the model versus the ownership of the training data, and whether it's possible, legal, and ethical to make profits off this model. Disclosing that work is coming from, or in part from, a generative AI theoretically means that there is no misrepresentation.
Academic Context
Is this technically plagiarism?
It's not directly copying off someone else's work, but it is potentially passing off work generated by this service as your own. For collegiate level work, this may be acceptable but largely discouraged. In fact, most students may choose to actively not use it on assignments of any value to them. It's hard to create high-quality work; it's harder to take potentially low-quality errors generated by something else and fix all of them to create high-quality work.
For other education levels, specifically up to high school (using the American system of education, since that is what I am most familiar with), this may be more concerning. Consider writing a report on a book chapter. If ChatGPT outputs a few errors, the student can claim that they wrote the few errors. Traditional methods like turnitin.com to check plagiarism wouldn't work, since exact substring matches won't be found. There may be checkers in the future to determine whether an AI or a human generated something, but those may not be 100% accurate and can always be disputed. These checkers are often trained alongside the generative AI model, and thus can be used as a baseline.
As an analogy - this is akin to getting math problems, but having a calculator to solve them. It may be possible to require things like "work", analogous to planning documents and drafts, but the key concern here is the levels at which they become relevant. A calculator may be important for doing simple algebra, but the hardest part about math problems isn't being able to compute large square roots; it's knowing which square roots may need to be computed in the first place, the general problem solving methodology. This analogy, this, is flawed in some ways; apps that are able to solve more complex math problems may be the better analogy, though those aren't as popular or as applicable.
From an idealistic standpoint, it is quite concerning to have younger students develop a reliance on generative AI. When used as a tool to assist, AI can be powerful and lead to insights. If it is solely used, e.g. a prompt is copied in and the output is pasted as the submission, the student may as well not be doing the assignment. Perhaps a student is reading the submission, but the merits of the assignment come from doing the assignment, a key portion missing in this workflow. I anticipate in-person exams will become more prevalent and more important to combat this.
Corporate Context
Can companies use this?
I want to preface this section by stating that I have no experience and a minimal understanding of the law, and this may largely be incorrect.
One aspect of this is for the legal liabilities of what these models produce. If Copilot introduces code that has a severe security vulnerability, is it GitHub's fault? Probably not, since the engineer that decided to use the suggestion is the one at fault, the same way that copying StackOverflow posts that may be incorrect doesn't put StackOverflow at liability.
But there is an interesting question here as to what parts of this a company owns and is able to use. If a model is trained on publicly available data, that is free to use for commercial purposes, that seems doable. If a model is trained for nonprofit uses, that might seem sketch in some cases if the underlying input data is not publicly availably or free to use, but there's some hesitation since the purpose is ultimately nonprofit.
There's currently a lawsuit being filed against Copilot that claims the model "relies on unprecedented open-source software piracy". The lawsuit is still developing, and is likely to have implications on the whole of generative AI and may potentially set precedent for the future as well. Similar claims have been made on other generative AI, such as against Lensa. Lensa creates AI images given a series of images about yourself, for a fee. But the underlying images used to train the model are largely taken from artists across a variety of media, with no portion of the proceeds going to them or any agreement to use their media. And, of course, this raises ethical questions.
If I was more interested in law, I'd look into this more. I'll leave it at this, though.
Generative AI is rapidly developing. It'll be interesting to see how it evolves, and we can hope that it evolves in a responsible way.
Found this interesting? Subscribe to get email updates for new posts.
First Name
Last Name
Previous Post
'Tis the Season of Retool